Welcome to Moonshine News!
Welcome to Moonshine News, your reliable and accessible source for the most recent updates in the tech world. We deliver noteworthy insights from both the academic sector and the bustling industry scene, covering intriguing topics like low-level operating systems, cybersecurity, and artificial intelligence. The information shared through Moonshine News is mainly gathered from my meticulously managed RSS feed and Google Scholar subscriptions. Part of the content is written with the help of GPT-4. I created Moonshine News with the idea of centralizing these valuable resources, making it easier for me to share them, instead of scattering links across multiple platforms and conversations. Consider Moonshine News as your one-stop for relevant tech news and discourse!
Note: Moonshine News currently does not have a regular publication schedule.
Cape API: Keep your sensitive data private while using GPT-4
- Source: Hacker News (Show HN)
- HN Link: https://news.ycombinator.com/item?id=36492149
- Link: https://capeprivacy.com/
Brief Summary:
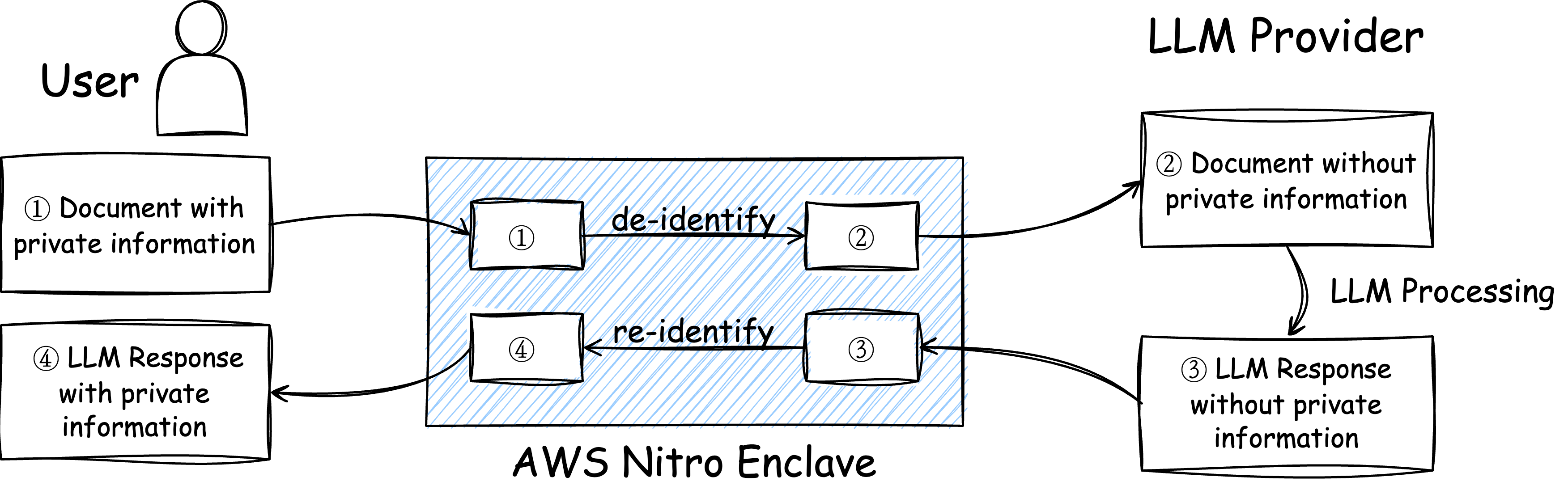
Cape API has been developed to allow developers to keep sensitive data private while using language models like GPT-4 and GPT 3.5 Turbo. With Cape, developers can de-identify sensitive data before sending it to OpenAI, create embeddings from sensitive text and documents, perform vector searches for improved prompt context, and keep the data confidential. The API features include de-identification of PII, PCI, and PHI from text and documents, re-identification of de-identified data within a secure enclave, document uploads in various formats (PDF, Excel, Word), vector search on embeddings within the secure enclave without external calls or sub-processors. Cape aims to address privacy concerns when using AI language models by providing solutions for ensuring data privacy and security during processing with LLMs.
Cape API Illustration
Key concepts:
- AWS Nitro Enclave: An isolated secure virtual machine provided by AWS. Everything inside the secure VM cannot be seen by the cloud service provider. Only the user can communicate with the secure VM using an encrypted communication channel.
- De-identify: I tried Cape myself. Based on my experience, de-identify basically means replacing all personal information with some placeholders. For example, Alice turned into [name_1], Apple turned into [company_1], etc. It also takes care of numeric information like credit card numbers. After de-identifications, the file sent to LLM providers (like OpenAI) contains no private information.
- Re-identify: The LLM generates responses with the placeholders. And inside the enclave, the placeholders are filled back in with according to a previously recorded table.
Comments:
- Cape does solve part of the problem. It effectively prevents information leakage to companies like OpenAI. However, the LLMs will not be able to see the literal relations between the hidden information so they will lose some power as a trade-off.
- In the long term, the LLM providers can deploy their models directly into secure VMs like AWS Nitro Enclaves, so that both user privacy and model privacy are well protected. Currently, this has not been true due to problems like how to securely assign (possibly multiple) GPUs to the secure VMs, how to maintain a high memory bandwidth while keeping everything encrypted, etc.
Related:
- AWS Nitrogen looks cool. It can be used to deploy existing web services to AWS Nitro Enclaves.
WiscSort: External Sorting For Byte-Addressable Storage
- Source: Google Scholar
- Link: https://www.vldb.org/pvldb/vol16/p2103-banakar.pdf
Brief Summary:
The paper describes a sorting algorithm, called WiscSort, that takes into account device concurrency constraints and interference with other processes. The paper shows that WiscSort outperforms other sorting systems that do not consider these factors. The thread-pool controller in WiscSort determines the appropriate thread pool size for a given operation, and the interference-aware scheduling ensures that short transactions are not delayed during long read phases. The paper also highlights the importance of utilizing the concurrency feature of the device and demonstrates the robustness of WiscSort with varying degrees of I/O interference intensity. Finally, the paper compares WiscSort with other sorting systems, including traditional external merge sort and Modified-Key Sort, and demonstrates that WiscSort is a practical external sorting algorithm that is competitive with other systems.
Key concepts:
- Byte-addressable storage (BAS): Byte-addressable storage (BAS) is a storage medium that allows access to small data regions without the amplification of page granularity requests. This property helps reduce unnecessary data movement over the memory bus and does not waste bandwidth unnecessarily. BAS has higher random-read performance compared to sequential read performance for larger accesses. The BRAID model specifies the important properties that distinguish BAS from other storage media. The model has five properties, including byte addressability, higher random-read performance, and asymmetric read-write cost, among others. Several BAS devices are set to be released soon, including Samsung CXL Memory Semantic SSD, Kioxia CXL 3D flash memory, and Everspin STT-RAM, due to the growing industry’s transition towards the CXL standard. BAS devices are expected to return over CXL, with similar properties as byte addressability, improved random-read performance, and read-write asymmetry. WiscSort is a sorting system that complies with the BRAID model and delivers sub-optimal performance than other state-of-the-art sorting systems. It carefully reduces writes, exploits random reads by splitting keys and values during sorting, and performs interference-aware scheduling with thread pool sizing to avoid I/O bandwidth degradation. Overall, BAS is a storage medium that has unique properties and is being developed further to meet industry demands.
Try: run a command and inspect its effects before changing your live system
- Source: Hacker News
- HN Link: https://news.ycombinator.com/item?id=36461102
- Link: https://github.com/binpash/try
Brief Summary:
Try is a command that allows you to run a command and inspect its effects before changing your live system. It uses Linux’s namespaces and the overlayfs union filesystem to create an overlay environment. You can pre-execute a command and commit its result at a later time by using the -n flag or specifying your own overlay directory.
Key Concepts:
- Overlayfs: This is the same technique used for docker images. It is essentially a copy-on-write filesystem.
Comments:
- Cool utility. It provides similar dry-run functionality to
make -n. I have been using it for potentially pernicious commands on my system. - Note: It is not meant to be used as a sandbox since the isolation level is not strong enough.
LLM Powered Autonomous Agents
- Source: Hacker News
- HN Link: https://news.ycombinator.com/item?id=36488871
- Link: https://lilianweng.github.io/posts/2023-06-23-agent/
Brief Summary:
LLM-powered autonomous agents use large language models as their core controllers. These agents have several key components, including planning subgoals and decomposition, reflection and refinement, memory (both short-term and long-term), and tool use. Planning involves breaking down complex tasks into smaller subgoals to efficiently handle them. Reflection allows the agent to learn from past actions, make improvements, and correct mistakes. Memory includes both short-term memory for in-context learning and long-term memory for retaining and recalling information over extended periods. Tool use involves the agent calling external APIs for additional information that may be missing from its model weights. The article also discusses different techniques such as task decomposition using prompting or human inputs, self-reflection through reasoning trajectories or heuristic functions, and algorithm distillation for improving performance based on past outputs. Finally, it explores different types of memory in human brains and how they can be mapped to LLM-powered agents' capabilities.
Comments:
- A very comprehensive review. Highly recommended. The article discusses many different attempts to create autonomous LLM agents.
- In the near future, multimodal neural networks are to be equipped with sensors and these autonomous LLM frameworks. Real useful personal AI assistants are on the horizon.
Related:
Gandalf – Game to make an LLM reveal a secret password
- Source: Hacker News
- HN Link: https://news.ycombinator.com/item?id=35905876
- Link: https://gandalf.lakera.ai/
Brief Summary:
This is a recently popular game about LLM prompt injection.
Key Concepts:
-
Prompt injection: The website itself contains a great introduction to prompt injection. Here I shall only mention the key ideas. In cybersecurity, it is well-known that “all user inputs should be considered dangerous”. For example, SQL injections happen when user inputs are mixed with database query commands. It is demonstrated by the famous xkcd 327 Yonkoma manga:
SQL Injection There has been a long battle against all sorts of SQL injections. And now we are facing a similar challenge for the LLMs: a malicious user may brainwash the LLM to disobey the original instructions. However, it is much harder to deter these attacks this time, since we currently have not developed an effective theory about what is actually going on inside the neural networks.

LLM Injection
Comments:
- Highly recommended. Try the game yourself, each time for a few minutes. It is really fun!
- As you pass to higher levels, you will gradually convince yourself that LLM prompt injection is a real thorny problem in the way of real-world LLM deployment.